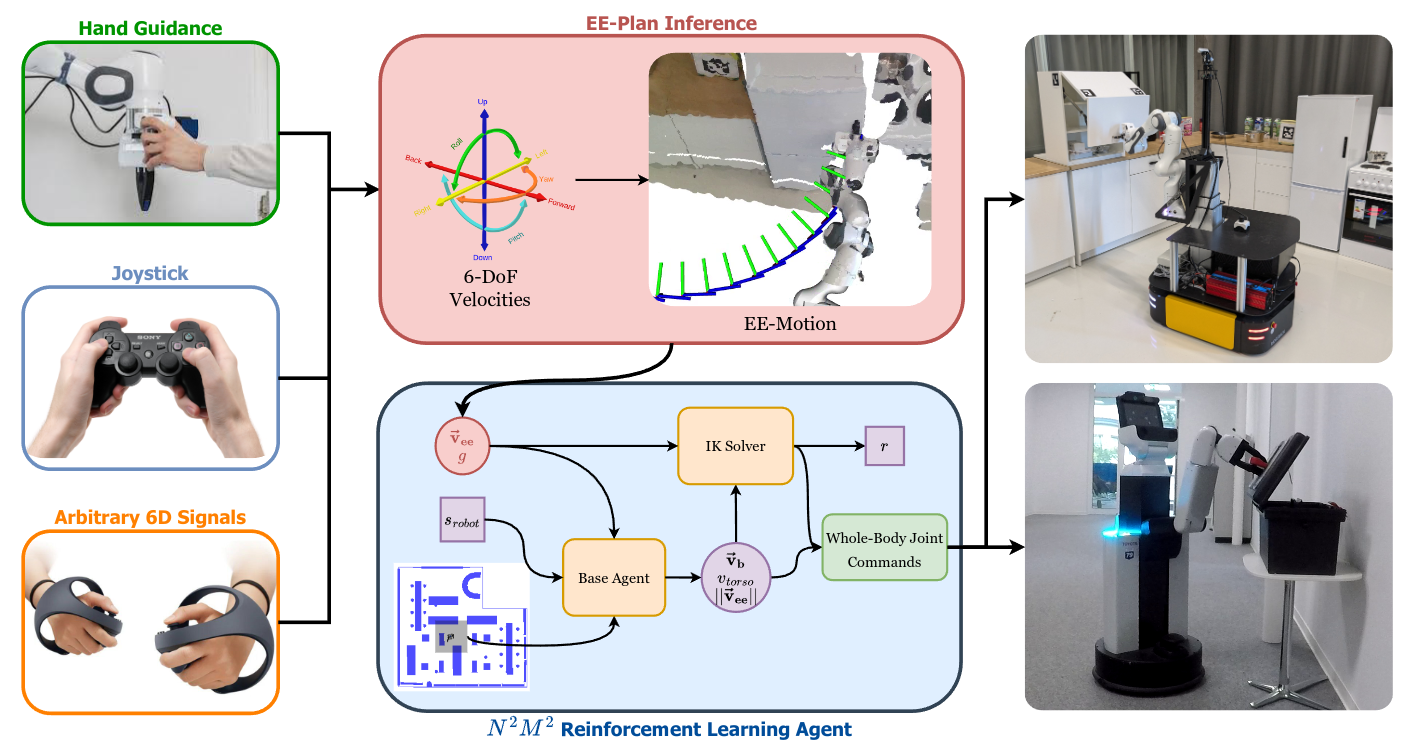
Demonstration data plays a key role in learning complex behaviors and training robotic foundation models. While effective control interfaces exist for static manipulators, data collection remains cumbersome and time intensive for mobile manipulators due to their large number of degrees of freedom. While specialized hardware, avatars, or motion tracking can enable whole-body control, these approaches are either expensive, robot-specific, or suffer from the embodiment mismatch between robot and human demonstrator. In this work, we present MoMa-Teleop, a novel teleoperation method that delegates the base motions to a reinforcement learning agent, leaving the operator to focus fully on the task-relevant end-effector motions. This enables whole-body teleoperation of mobile manipulators with zero additional hardware or setup costs via standard interfaces such as joysticks or hand guidance. Moreover, the operator is not bound to a tracked workspace and can move freely with the robot over spatially extended tasks. We demonstrate that our approach results in a significant reduction in task completion time across a variety of robots and tasks. As the generated data covers diverse whole-body motions without embodiment mismatch, it enables efficient imitation learning. By focusing on task-specific end-effector motions, our approach learns skills that transfer to unseen settings, such as new obstacles or changed object positions, from as little as five demonstrations.